One of the fundamental building blocks of conversational AI is understanding natural language. AI agents need to understand what a user has just said in order to react accordingly. In this post I’ll give an intuitive explanation about how we solve this problem using the PolyAI Encoder model.
Let’s start by looking at how humans understand each other.
For us, language is as much about the relationships between words as it is about the words themselves. We use metaphors of distance, location and direction to distinguish sentences based on their similarities and differences. For example, “I am happy” and “I’m over the moon” are very close in meaning. “The movie was great” and “It was so boring I fell asleep in the cinema” are opposites.
We also describe the different degrees to which sentences can differ. “Yes!” and “yeah!” are almost identical, “how are you today?” and “how are you feeling after yesterday?” mean slightly different things, but they are much closer in meaning to each other than they are to “why is the sky blue?”
Computers, on the other hand, only see language as writing: a chain of letters, numbers and punctuation. There is no easy way for a computer to understand that two sentences are similar in meaning.
The PolyAI Encoder Model is our solution. Just like us humans, the Encoder Model groups chunks of language together in terms of their similarities and differences. Therefore, the model can understand the meaning behind complex sentences, regardless of the way they are phrased.
The Encoder Model is a pre-trained language understanding module that enables us to build production-ready AI agents with human-level understanding in a matter of hours. In this post, we’ll give a simple explanation of how the Encoder Model works and how it compares to other technologies on the market.
The PolyAI Encoder Model
The Encoder model places every sentence it sees within a high-dimensional space. Sentences that are close together in this space are likely to have very similar meanings, whereas groups of sentences which differ in some way (e.g. one group of positive sentences and a group of negative sentences) will occupy different areas of the space.
Let’s look at a toy example.
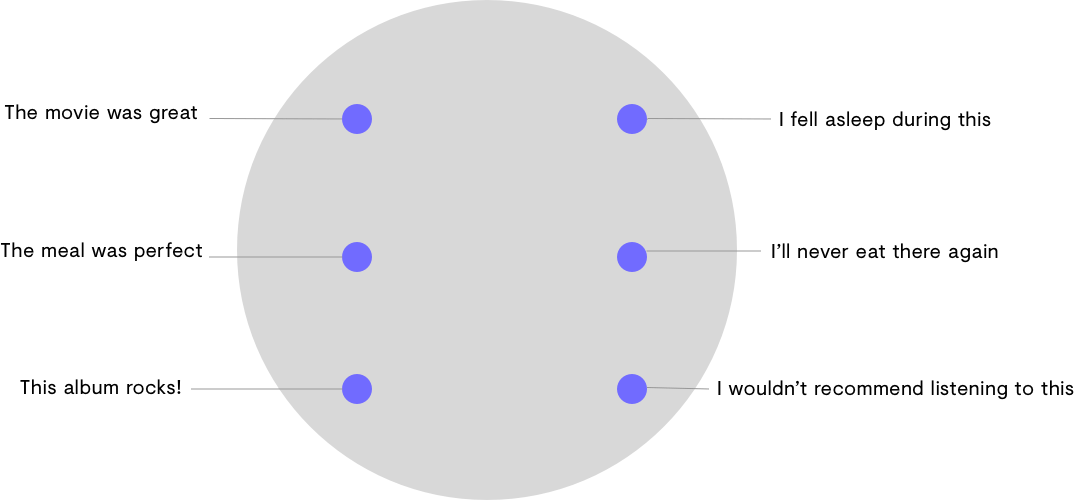
The above diagram shows six sentences that have been placed in a 2-dimensional space by an encoder. They can relate to each other in a couple of ways:
If we look at these sentences along a horizontal axis, they can be understood as opposites. These groups can also be thought of as topics: movies, restaurants, music.
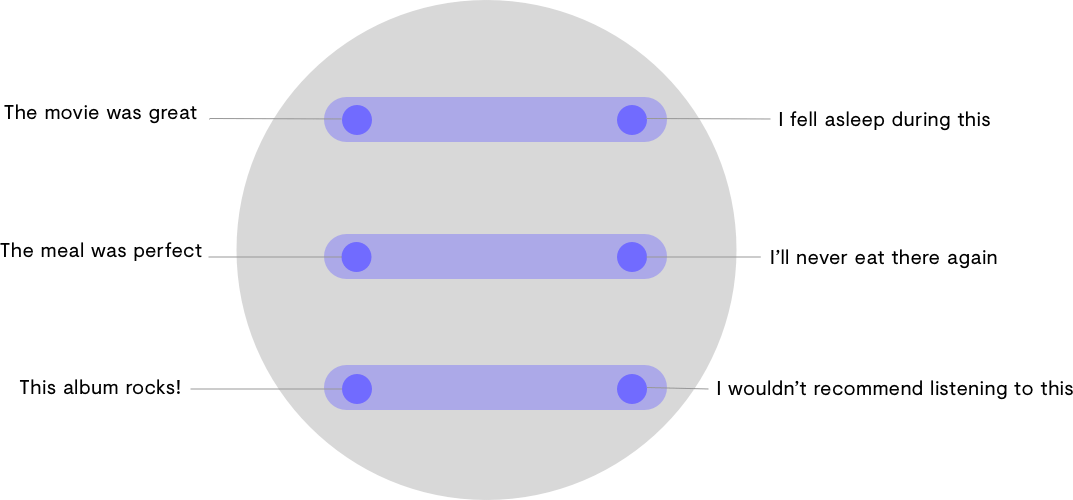
But if we look at them on a vertical axis, they can be understood in terms of sentiment, with positive statements on the left and negative statements on the right.
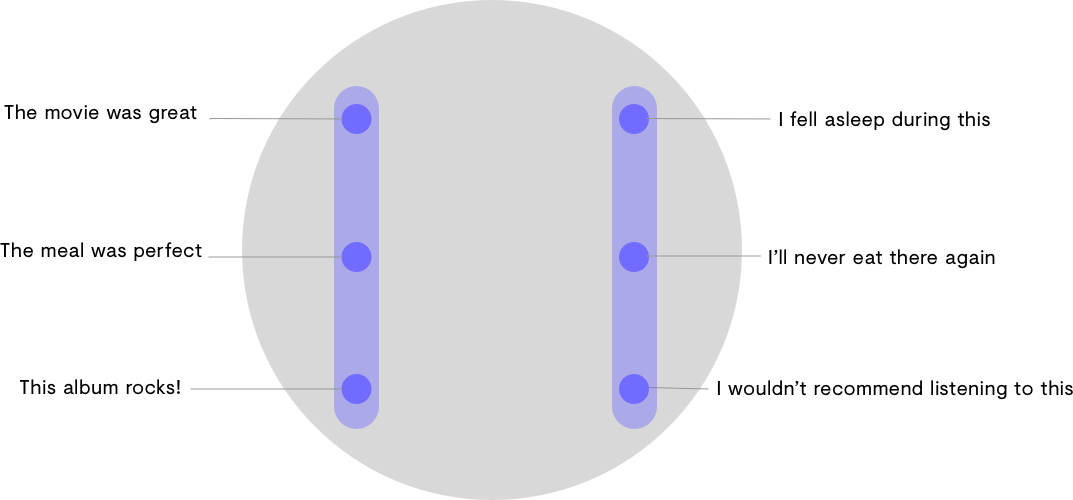
If we were interested in knowing whether a sentence was positive or negative, it would be as simple as seeing whether the encoder model places it on the right or left side of the space. If we wanted to know whether a sentence is talking about movies, food, or music, we would look at which section of the space (top, middle, or bottom) the encoder places a sentence.
Now this example only shows two dimensions, but the Encoder Model actually places sentences in a space consisting of hundreds of dimensions. This means it can group ‘chunks’ of language based on any kind of correlation, including none at all.
Why is the Encoder Model important?
Because the Encoder Model already has a good grasp of language, we can build accurate conversational systems much faster.
Most conversational AI companies can (and do) create AI agents without a pre-trained encoder model. This means they need to train their model from scratch, relying on their clients to provide hundreds of thousands of conversational examples (like historic customer service calls) that can be used for training. Not only does this information need to be provided, but it needs to be labelled in such a way that the model can make sense of it, a job that will take serious time in itself. And even when enough high quality data can be found to train the model, it’s still limited to conversations your customer service agents have previously had with customers, which is a very limited sample in the wide scale of things.
Many conversational AI companies will turn to services like Amazon Mechanical Turk (MTurk) to crowdsource the conversational examples they need for training. This involves paying a very small ‘bounty’ for MTurk workers to provide examples. The issue here is that the workers often provide poor quality and duplicate examples. And for the fees they’re getting, you can’t really blame them.
There are open source encoder models – such as USE and BERT – that are available for anyone to use. There’s a couple things that make these models less than ideal for commercial applications.
Firstly, these models are developed by academic research groups – they aren’t built with production in mind. These models tend to use so much memory on a computer that they’re difficult to run in production. In comparison, we designed the PolyAI Encoder Model to easily run on your laptop, and to perform better than USE and BERT for conversational NLP tasks.
Secondly, as with all open source technology, these encoders are not within the control of the people using them. They could stop being supported at any time. And even if they do run smoothly, when the models don’t perform how you expect them to, it can be difficult to find out why and rectify problems. For example, if you’re using an open source encoder in a scenario where race or gender is mentioned (such as job applications, insurance payouts etc), you want to have to have control over bias mitigation. Even in less sensitive contexts, the ability to diagnose and fix issues within the model is crucial to keeping costs down and performance up.
Because we’ve created our own Encoder Model, we know it inside out; we know how it works and we know how to make it perform in line with our clients’ and their customers’ expectations.
Understanding is performance
This level of deep understanding is key to developing virtual agents and assistants with whom customers can speak freely and naturally. Without this understanding, technology will be limited to IVR-style conversations like ‘press 1 for sales’ or ‘if you’d like help with your credit card say “credit card”’.
Most companies building commercial conversational AI solutions will require huge amounts of data from their clients, and even then, they’ll need to hand-craft a number of conversational flows manually to account for the inaccuracies in their models.
The PolyAI Encoder Model has enabled us to understand language off the shelf, meaning our clients only need to provide very small amounts of contextual data (such as their knowledge bases or FAQs) to teach the model the intricacies of their customer service requirements.
If you’d like to learn more about the PolyAI Encoder Model, get in touch with us today.