In artificial intelligence and speech synthesis, the quest for more natural and realistic voice interactions is a priority. At PolyAI, we’re committed to creating customer-led voice assistants. This means voice assistants that give callers the freedom to speak however they like and the confidence that they will receive useful responses.
While we do a lot of work around Natural Language Understanding (NLU), we also think about understanding in the most literal sense – accurately “hearing” what the caller is saying. This is difficult over the phone due to poor connections, background noise, and different accents.
As such, we invest heavily in Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) research. In this article, we will delve into our latest vocoder model and discuss the challenges of scaling it to unprecedented size.
We care about voice
We aim to create more natural, human-like interactions between AI-powered systems and users by developing our own speech recognition and text generation models. Focusing on voice technology is crucial in bridging the communication gap between humans and machines.
Text-to-speech models
A typical TTS model comprises an acoustic model that generates mel-spectrograms and vocoders.
- Mel-spectrograms capture information about speech sounds’ pitch, duration, and intensity.
- Vocoders synthesize the final audio waveform from these spectrograms, creating audible speech.
By improving these components, PolyAI strives to enhance the quality and naturalness of synthesized speech, making AI-generated voices virtually indistinguishable from human speech.
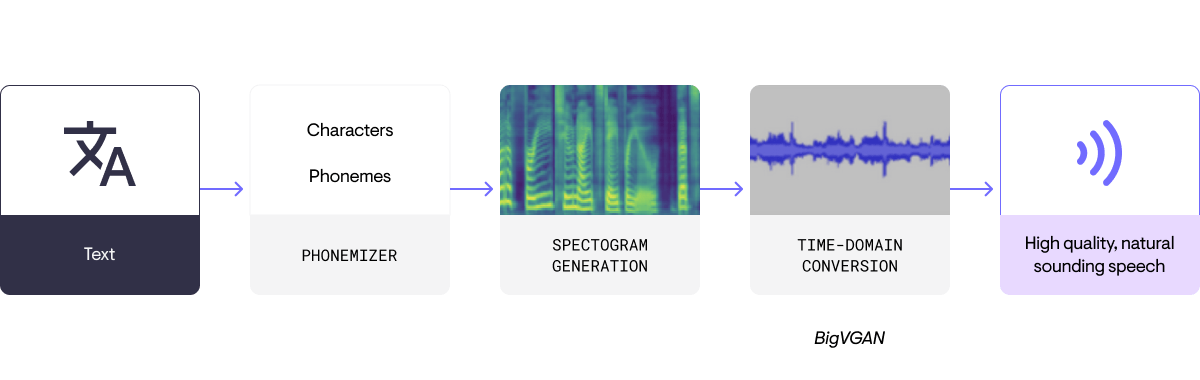
BigVGAN
BigVGAN is a powerful model designed to scale GAN-based models to large sizes and datasets created by a team of researchers at NVIDIA. By harnessing the capabilities of Generative Adversarial Networks (GANs.), BigVGAN can generate high-quality, natural-sounding speech across various languages. This makes it a valuable solution for multilingual TTS applications and marks a significant step toward creating a global TTS system that caters to diverse linguistic needs.
BigVGAN utilizes advanced techniques such as periodic activation function and anti-aliased representation into the GAN generator, which brings the desired inductive bias for audio synthesis and significantly improves audio quality.
At PolyAI, we decided to scale things further by training the largest universal vocoder on the market. This allows the incorporation of a larger amount of different languages, dialects, and data sources to improve the model’s quality.
Challenges of scaling
Scaling GAN architectures is not without its difficulties, as they are prone to collapse and can be quite brittle. To push the limits of our model, we wanted to increase its size even further. Our machine learning team optimized a variety of hyperparameters, ultimately arriving at a 300-million-parameter model. This model is three times larger than existing models, enabling us to generate even more realistic and natural-sounding speech. We have set a new standard for vocoder performance in overcoming these challenges.
Some of the techniques we employed to address these challenges include gradient penalty regularization, adaptive learning rates, and architectural modifications. Gradient penalty regularization helps stabilize training and prevent mode collapse, while adaptive learning rates ensure that the model can effectively learn from the data. Furthermore, we made architectural modifications to the generator network to ensure it can handle the increased complexity of the larger model.
Evaluation and benchmarks
To evaluate the performance of BigVGAN, we use two standard automatic metrics.
- A standard machine learning metric informing how close to the original mel-spectrogram are the generated samples. The lower the score, the better the resemblance to the original audio.
- Perceptual Evaluation of Speech Quality (PESQ). This is a recognized industry standard for audio quality that takes into consideration characteristics such as: audio sharpness, call volume, background noise, clipping or audio interference. PESQ returns a score between -0.5 and 4.5, with the higher scores indicating a better quality.
Training Error | PESQ | |
Best SoTA | 0.0722 | 4.2501 |
PolyAI | 0.059 | 4.2857 |
Sharing the goodies
To further contribute to the research community and promote collaboration, we are excited to announce the release of BigVGAN-L on the Hugging Face Model Hub at https://huggingface.co/PolyAI/BigVGAN-L. Researchers and developers can now access and fine-tune on top of our vocoder in their own applications. By sharing our work with the community, we hope to inspire further advancements in speech synthesis, promote open discussions, and accelerate the development of new applications and innovations that leverage the power of cutting-edge vocoders like BigVGAN. We encourage researchers to explore, experiment, and build upon our model to push the boundaries of what’s possible in the realm of TTS technology.
Summary
PolyAI is always on the lookout for talented individuals who are passionate about building better models and revolutionizing the field of speech synthesis. If you’re interested in working on cutting-edge foundational models and want to be part of a team that is shaping the future of Conversational AI, consider applying to PolyAI. You can submit your application through Workable.


