
Table of Contents
TL;DR
- Raven v2 outperforms models like GPT-4o and Claude in both internal benchmarks and live A/B tests.
- Raven v2 handles complex instructions, multi-turn flows, and real-time function calls with precision.
- PolyAI’s proprietary stack gives it full control over model behavior, latency, and deployment.
The latest model is faster, more accurate, and easier to control, enabling the best customer conversations at enterprise scale.
Raven v2 is PolyAI’s latest in-house LLM, purpose-built for customer service conversations. The model is already live serving multiple enterprise customers, with impressive initial results around engagement and resolution. Built on PolyAI’s customer-service expertise and real-world feedback, Raven v2 intelligently decides how to respond in each scenario and when to trigger agentic tools that demand precision and real-time performance.
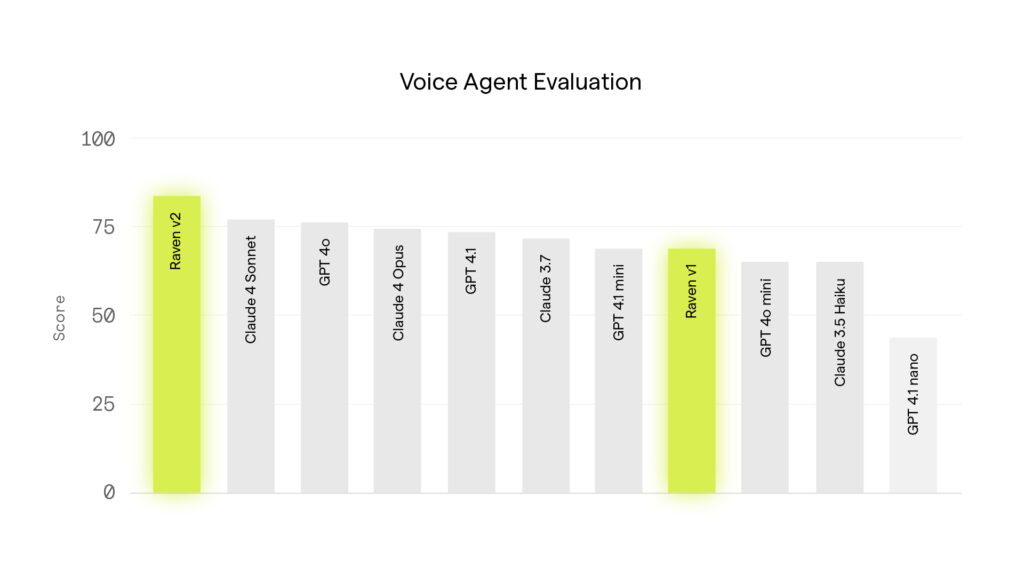
Raven v2 outperforms general LLMs
Voice agents built in PolyAI’s Agent Studio are powered by Large Language Models orchestrated in an agentic loop for live conversations. They must deliver accurate, real-time responses while handling long-context, instruction-heavy prompts filled with business rules and edge cases – a challenging task where even 100 ms of latency can be noticeable to the end user.
Our internal benchmark tests performance on real-world customer service interactions, testing instruction following, function calling, question answering etc. Raven v2 comfortably outperforms all general purpose LLMs in this evaluation, including models from OpenAI and Anthropic. Its targeted training has taught it to excel at following complex instructions and to return precise, real-time responses in live customer conversations.
Raven v2 is specifically tuned for live voice conversations, where responses need to be accurate, robust, and fast. General-purpose models like GPT and Claude are overly specialised to long-form, text-based chatbot use cases. In voice settings, they often struggle with understanding what the user has actually heard, since users do not see tool calls or their outputs. They frequently mismanage turn-taking and can fail to decide correctly when to speak to the user versus when to invoke a function. These models can also get confused in structured conversational flows that require gathering information over multiple turns. For example, when booking a reservation, they may skip asking for key details like name, time, or party size, instead filling in placeholders or guessing values. Raven v2 avoids these errors because it is tuned specifically for the demands of spoken dialogue.
Under the hood of Raven v2
Raven v2 is faster and more accurate than our earlier v1 model. We used feedback from v1 deployments to improve our evaluation and training pipeline, resulting in a significantly stronger model. We made advances in the model’s prompt representation, reducing output tokens and improving prefix cache efficiency, which directly improves latency.
Raven v2 is faster. It is a quantized model optimized for fast time-to-first-token, enabling near-instant responses. Because function definitions in AI agents are often dynamic, we place them later in the prompt to improve prefix cache hit rates, allowing more requests to reuse cached context. Additionally, a more compact function-calling output format reduces average output by 18 tokens, further cutting latency. Raven v2 is also hosted on our own dedicated infrastructure, co-located with the rest of our system, avoiding the delays that come with third-party hosting and shared queues. These combined optimizations result in a system that feels faster and more natural to talk to.
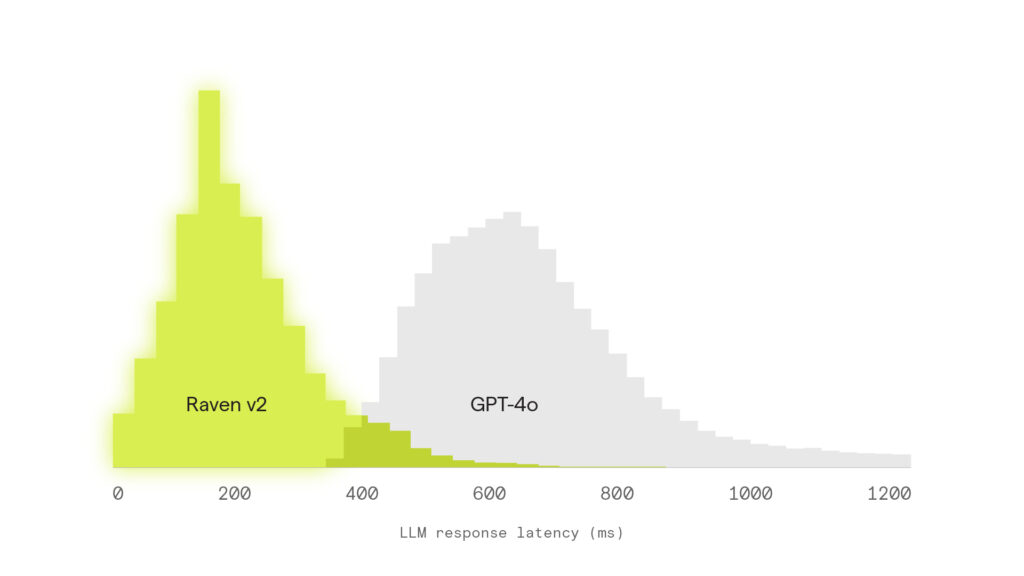
In live A/B deployments, Raven v2 consistently delivers lower latency than general-purpose models like GPT-4o, as shown in the chart above. In voice interactions, this kind of speed difference is perceptible. Faster responses mean tighter turn-taking, smoother conversations, and a more human-feeling experience. This also frees up time for the system to spend more time reasoning about its final answer.
Raven v2 is more accurate. It is trained on 3× more data across 4× more domains than Raven v1, making full use of a type of data unique to PolyAI: realistic examples of prompts crafted by expert system designers for live deployments across a multitude of domains, including healthcare, financial services, hospitality, etc. We improved our relabelers and preference judges using insights from v1, and we leverage large reasoning models to guide Raven v2, distilling their instruction-following capabilities into a much faster, smaller model.
Why does PolyAI build its own models?
General purpose LLMs aren’t optimized for structured, goal-directed dialogue. Owning the model gives PolyAI more control over latency, behavior, and deployment flexibility, allowing us to optimize every deployment for a given use case. This is a core differentiator to other customer service AI vendors in the space, PolyAI is not an LLM-wrapper company, we have our own proprietary technology stack.
What’s next?
From a research point of view, PolyAI is continuing to invest and expand in optimizing customer service conversations. We’re investing in further conversational reinforcement fine tuning, expanding multilingual capabilities, optimizing for conversational human-like style, and developing latency-sensitive approaches to reasoning. The research team is continuing to build and train models where it matters, facilitating natural end-to-end conversations across platforms.
The research team is hiring! We’re a creative team rethinking how language models are built and trained for real-time spoken dialogue. With access to one of the richest conversational datasets out there, we explore ideas that go beyond the standard playbook. We’re remote across the UK. Check out our job board or reach out to Matt to learn more.
This was co-authored with Paula Czarnowska, Leo Bujdei-Leonte, and Luca Furtuna, thanks for their contributions and hard work.