
Intent detection is the task of classifying a user’s intent. For example, in the hospitality industry, intent categories might be ‘make a reservation’, ‘cancel reservation’, ‘update reservation’ etc. While this is a key part for any conversational AI platform, it is a somewhat under-resourced area of research.
Publicly available intent datasets are usually very small and artificial, focusing on tasks too simple to be meaningful. They rarely have more than 10 intents, and these are typically too simple to be useful.
While PolyAI’s long term vision is to rely on less constrained approaches, accurate intent detection is a key aspect of current conversational AI solutions, and is the first point of failure of any conversational agent. If the user intent is detected wrongly, then it doesn’t matter how sophisticated your dialogue model is, the conversation is not going to be useful for its users.
Real world applications might have hundreds or even thousands of intents. And the more intents we have, the more likely it is that several of these intents will be very similar and therefore easier to confuse. Large commercial systems (such as all the big brand intelligent assistants out there) attempt to solve this problem by collecting millions of examples from their users.
So how will businesses go about employing conversational AI in commercial settings? Most companies won’t have access to this level of data from their customers, so the intent detection model must work well in low data settings (in academic terms, generalisation), and must also make highly accurate predictions. Additionally, in real life, users will expect real-time responses, so the model must be computationally efficient and ready to scale to a large user pool.
At PolyAI we are working to make conversational AI a commercial reality, so it’s key that our intent detector can work in real-life settings, with limited data. In this post, we’ll look at how our intent detector compares to others based on realistic datasets.
Benchmarking the PolyAI intent detector
We recently introduced the PolyAI encoder, a model trained on billions of Reddit conversations. While the model was originally trained to rank a list of responses based on a given input, we noticed that the model learns powerful and robust representations of sentences that generalise well. By training an MLP (multilayer perceptron) on top of these encodings, we got very promising intent detection results.

The benchmark datasets
The next step was to compare our intent detector to other top performing models so that we can be sure we’re coming out on top. But the lack of available intent datasets (especially “real-world” datasets) was a problem.
Over the last two years, we have been working on several “real-world” dialogue problems which required intent detection, so we’ve been able to put together data from the most representative projects we had worked on, creating a diverse set of datasets for benchmarking intent detectors on the market.
We decided to include an already studied task as a reference, so we added a publicly available dataset (SNIPS) to the benchmark.
The following table shows a brief description of the benchmarked datasets.
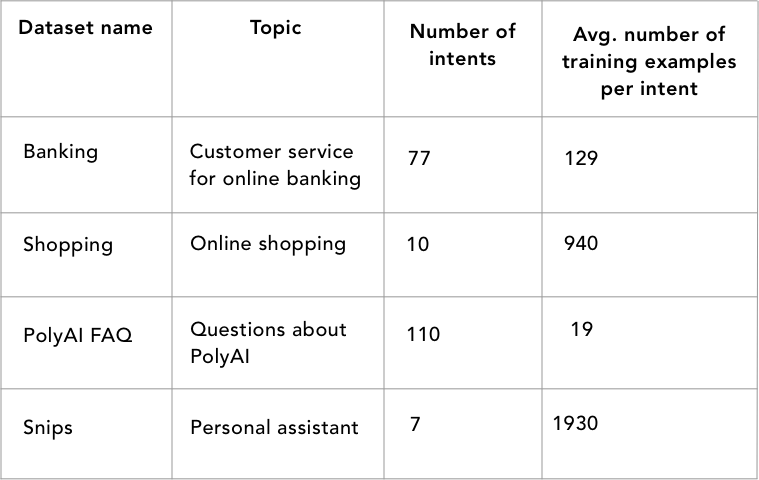
We also want to know how these models work when they are trained with different amounts of data. Therefore we created 3 data settings:
- Low: 10 examples per intent
- Medium: maximum of 50 examples per intent (30 for PolyAI FAQ)
- High: The full dataset
Comparison with commercial intent detection tools
We began by comparing our intent detector with some of the available commercial intent detection solutions. We selected 5 of the most popular language understanding toolkits on the market: Rasa, Twilio Autopilot, Dialogflow, MS LUIS, IBM Watson. The following chart shows the average results for each of the 4 datasets in each of the data settings.

You can see the full results for each individual dataset in this Google Sheet.
Our model clearly outperformed each of these solutions. But most importantly, in low data settings, our model performed more than an absolute 10% better on average.This means that with the same amount of effort, the PolyAI solution gives you an extra 10% accuracy for free, which could reduce the costs of prototyping a new conversational agent drastically.
Comparison with state-of-the-art sentence encoders
We also compared our model with state-of-the-art sentence encoders. We selected 2 of the most successful sentence encoders, BERT and USE, and trained an intent classifier on top of them, following the same structure that we used with the PolyAI encoder (with BERT, we actually fine-tuned all the parameters of the model, since this yielded much better results). The results can be seen in the following chart.
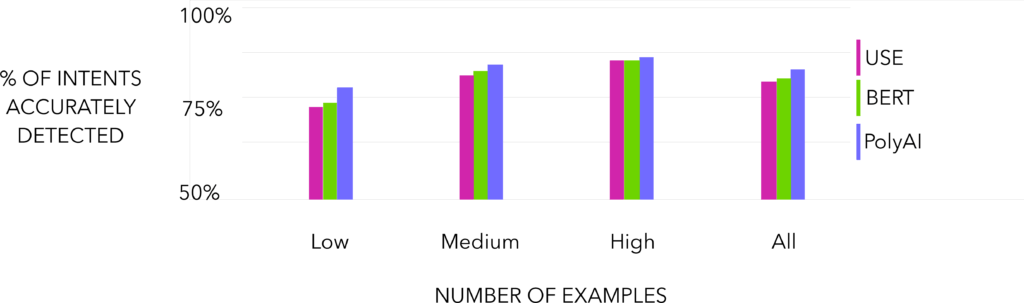
Once again, the PolyAI intent detector performed the best. And, as in the previous comparisons, the largest performance increase was obtained in low data settings. These results suggest that the PolyAI encoder is better suited for conversational tasks (sentence encoders are usually evaluated in diverse NLP tasks such as GLUE or SentEval, which are not very related to conversational tasks).
Most importantly, our model is much smaller and much faster to train (especially compared to BERT). This makes it more suitable for real applications. The following table gives an approximate idea of the size and training time difference:

* Source: syncedreview.com
We also found that the training of the PolyAI and USE intent detectors were much more stable than BERT, with the latter being more sensitive to changes in the model hyperparameters and initial random seed.
Conclusion
Our research has shown that we’ve created an intent detection model that:
- Outperforms commercial intent detectors by a large margin, especially on low data settings
- Outperforms intent detectors based on state-of-the-art sentence encoders
- Works well across different highly challenging intent detection tasks
- Is very lightweight
- Is very cheap and fast to train
This is only a simplified version of the model. Ensemble models, multi-task training, deeper hyperparameter search or deeper research on fine-tuning the full encoder have the potential to improve these results even further. In addition, the model is applicable to value extraction and multilabel intent detection by adding small modifications to the architecture.
Watch this space for a future publication with more details and datasets.
We’re hiring! Check out our open positions on polyai.com/careers.
Thanks to my colleagues at PolyAI, in particular to Tadas and Olly who helped me with the benchmarks, and Kylie and Shawn for helping with the writing.


