
In a recent evaluation by Salesforce Research, PolyAI’s ConveRT model performed top across a range of metrics, while using a fraction of the computational resources.
Salesforce’s recent paper, Probing Task-Oriented Dialogue Representation from Language Models, compared ConveRT to other pre-trained models, evaluating their ability to encapsulate conversational knowledge in application to Conversational AI tasks. ConveRT was compared to larger BERT and GPT-based models, including Salesforce’s own ToD (task-oriented dialogue) models.
Salesforce’s ToD models are trained on a variety of public dialogue datasets, including several from previous publications by current PolyAI team members: MultiWoz by Paweł Budzianowski, WoZ by Nikola Mrkšić, CamRest676 by Tsung-Hsien Wen, and DSTC2 by Matt Henderson (held-out for evaluation). These dialogue datasets constitute tens of thousands of examples. By contrast, ConveRT is trained on hundreds of millions of examples from online discussions.
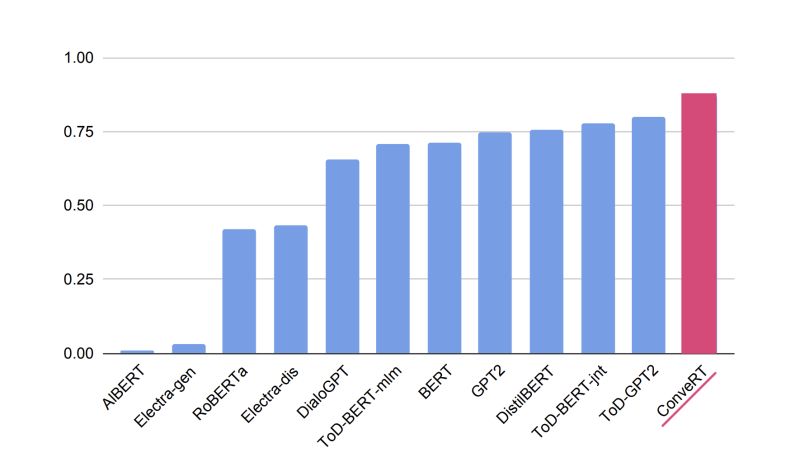
PolyAI’s ConveRT model performs top on three out of four of the classification probe evaluations, coming second place in the fourth. Further experiments show that the ConveRT and ToD models give more meaningful clusters than general purpose models like vanilla BERT and GPT2 that are not optimized for Conversational AI tasks.
Recall that ConveRT is significantly smaller and more efficient than BERT and GPT based models; it is more than ten times smaller, and far cheaper to train.
This evaluation serves as further proof that PolyAI’s ConveRT model is a state of the art approach for tackling Conversational AI understanding tasks. It is specifically optimized for dialogue, allowing it to be far more efficient than competing approaches.


