
The first phone call was placed on March 10, 1876. Graham Bell shouted at his assistant: “Mr Watson, come here — I want to see you!” This was a game changer. For the first time in history, we had real-time remote communication, and with it, the ability to remotely automate all kinds of services. In his case, Mr Bell could ask his personal assistant to run errands without ever seeing him in person. Of course, Mr Bell could have sent a letter, telegram or a pigeon, but this would not have been as fast or convenient as picking up his phone — it wouldn’t have been real time!
Over time, one could dial an increasing number of businesses and procure services remotely and in real time. However, there was no easy way to discover these services. The solution came with the Yellow Pages: large print directories listing local businesses and their phone numbers.
After a long wait, the World Wide Web moved the service directory away from dusty Yellow Pages into sleek and minimalist search engines. Users could read the latest news, order books, or even check the balance of their bank account without waiting for the phone operator on the other end of the line. However, websites forced users into structured interaction with backend systems, forcing companies to spend millions on user interface design to hook users to their service. Since there were no uniform design standards, users had to adapt to a different interface for each service, instead of using their voice alone.
Next stop, smartphones. With their limited screen real estate, smartphones posed new challenges for software and interface developers. Apple, in turn, set an amazing example for how to create extremely simple and intuitive mobile interfaces. These principles proliferated through the forthcoming AppStore. Despite the plethora of apps available, users are left to their own devices when choosing which app to download, and this is not always straightforward. In fact, the majority of US smartphone owners install zero new apps each month.
Following on from smartphones, operating system vendors now offer us Virtual Personal Assistants. Recent advances in machine learning have led to huge improvements in speech recognition, allowing companies such as Google and Amazon to bring voice-powered personal assistants to every home, phone, watch or any other piece of hardware fitted with a microphone. Instead of adapting to interfaces of third-party apps, assistants abstract them away, allowing users to access a plethora of services using their voice alone.
Personal Assistants like Siri, Alexa and Google Assistant aspire to be the de facto entry point for most actions that users might want to perform on their smartphones, smart homes, and other assistant enabled devices. Rather than forcing users to choose the right app, personal assistants provide a natural conduit for accessing third-party services. Since they are voice-based, they allow users to bypass graphical user interfaces altogether. This is especially intuitive for younger generations who have grown up accustomed to smartphones and other connected devices.
From search engines to mobile OS platforms, the contest between big tech companies has revolved around the control of platforms because they are the central point of access to billions of customers. For these revenue streams to come to life, personal assistant platforms have to connect to third-party services. If not, the assistants are empty-headed, like a Google without search results or an iPhone without its AppStore. In fact, Amazon’s Echo in many ways resembles the iPhone circa 2007. The first iPhone’s touchscreen took the world by storm, and similarly, consumers can’t get enough of the Echo, Amazon’s top selling item over last Christmas.
Platform providers want third-party apps for their personal assistants. Alexa Skills, Actions on Google, Azure Bots… all the giants are trying to make their platform the best ecosystem for building your voice-powered application. However, building conversational apps that people want to use is proving very difficult. Despite tens of thousands of deployed Alexa Skills, 62% of them have no user ratings, and only four have more than 1,000 ratings. Of the 16 top-rated Alexa Skills, 14 play ambient sounds, showing that we are still far off from using third-party voice apps to achieve complex daily tasks.
Conversational apps will not replace mobile apps, the same way that mobile apps did not replace the Web. Good voice-based apps will simply supplement existing interfaces for those scenarios where using your voice makes the most sense. Existing bot building services are just the beginning.
Tools like Google’s Dialogflow or Amazon Lex, as well as a number of other third-party developer tools have been trying to simplify conversational app design by using flowcharts coupled with basic machine learning models. These tools help developers hand-craft the flow of dialogue by conditioning the programmable system response on user input and preceding dialogue context. These tools work well for simple voice apps, such as the one that can order an uberX to your house. However, they can do nothing more involved.
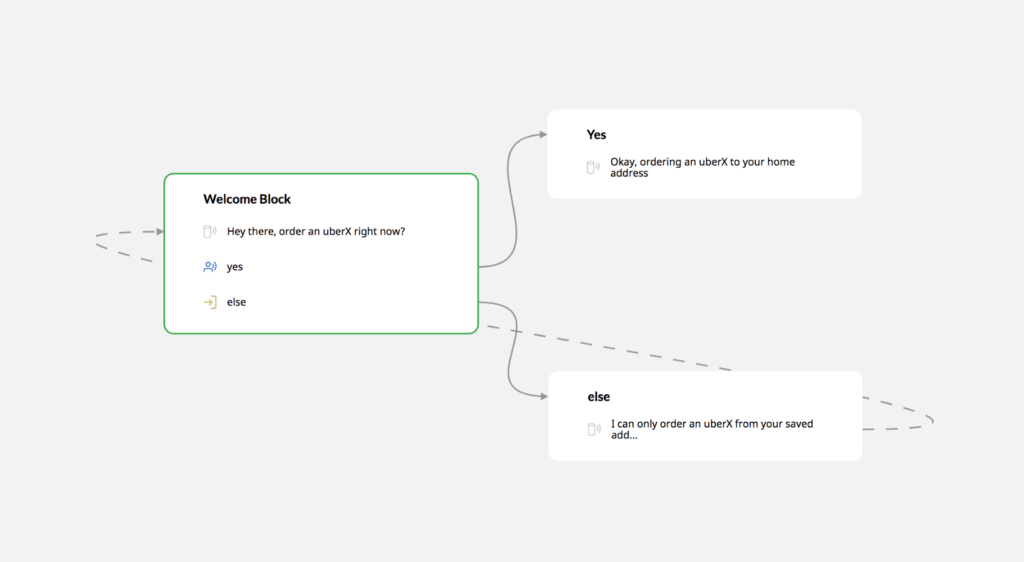
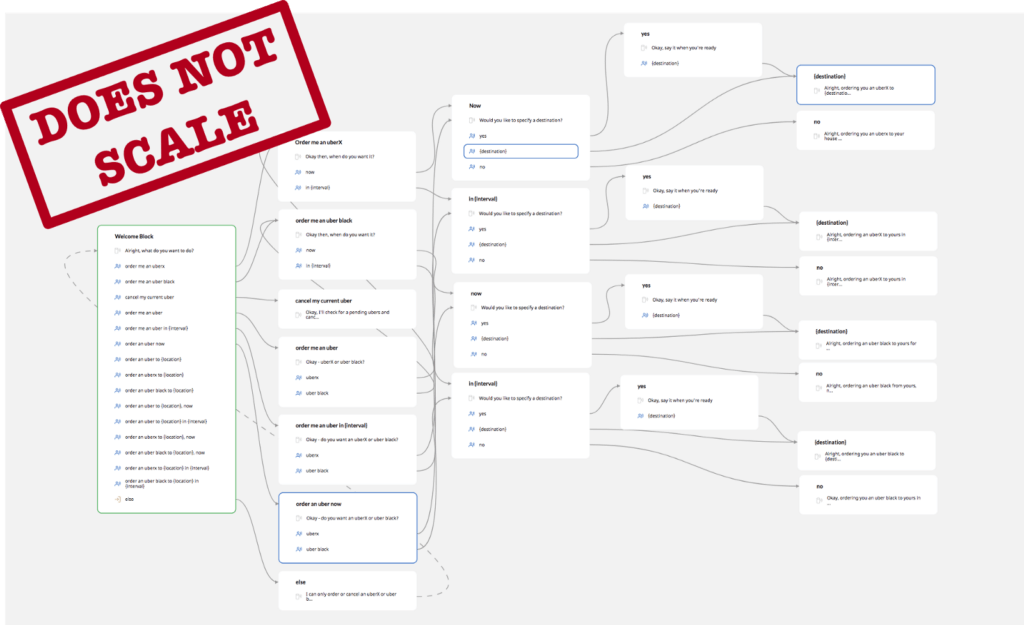
These tools have a fairly gentle learning curve and work well in theory. However, developers tend to find that creating an app that is seriously useful means they must cater to specific user preferences. In the Uber example, that means understanding whether the user prefers an UberX or an Uber Black, if they’re ordering right now or in 15 minutes, and to which destination? When speaking, users typically specify those conditions in any order they see fit. To handle all permutations of user input, the flowchart turns into something that becomes extremely difficult to manage or improve further.
This design paradigm means that developers need to specify the response for every possible user input and its preceding dialogue context. However, the more complex the domain, the more possible scenarios there are. In fact, the number of paths leading to successful dialogue completion grows exponentially with the complexity of the application domain! This makes it hard (if not outright impossible) to design voice-powered apps that can deal with tasks harder than setting an alarm or playing songs on Spotify.
PolyAI is a London-based technology company founded by three Cambridge lab-mates who spent the last four years in a PhD programme figuring out how to leverage the latest developments in machine learning to make spoken dialogue systems more powerful and much easier to design.
We founded PolyAI to show the world that spoken dialogue system design doesn’t have to involve brutal amounts of hand-crafting or gimmicks to guide users away from difficult use cases. By developing deep learning algorithms, we allow conversational agents to learn how to interpret what the user wants, and how to respond intelligently without having to follow a script. Our algorithms deliver such performance in a way which naturally supports multiple languages and application domains. That’s why we’re called PolyAI!
The era of Virtual Personal Assistants is here, but there is still much to do before we have the equivalent of an AppStore for assistant-enabled platforms. When Graham Bell invented the telephone, he could have hardly imagined its transformational impact. Similarly, it’s hard to say how fully functional and natural voice-based apps will affect our lives and the way we interact with technology. If you’d like to work on bringing the use of proper machine into the design of voice-based conversational agents, get in touch!


