
We’re thrilled to announce our recently published paper on the PolyAI ConVEx framework. Our new technique, ConVEx (Conversational Value Extractor), is the most accurate value extractor on the market. It requires significantly less data than previous best systems, which means that PolyAI can create virtual assistants faster and better than anyone else, across any customer service use case in any domain.
ConVEx is just one part of PolyAI’s proprietary technology suite which focuses on accuracy, speed-to-market, scalability and end-user/customer experience.
In this blog post, we’ll explain ConVEx in detail. If you’d like to know more about how PolyAI’s proprietary technology can deliver state-of-the-art voice assistants for your company, get in touch today.
***
Slot-labeling is the task of identifying key pieces of information from a user’s spoken instructions to a voice assistant. For example, an online banking assistant may need to extract the cash value and recipient in order to make a transaction on a user’s behalf:

Slot-labeling data is domain-specific and requires a significant manual effort to collect. This has made it hard for the industry to scale up assistants in new domains and languages. At PolyAI, we have solved this problem with ConVEx (Conversational Value Extractor), a slot-labeling approach that requires very little labeled data to achieve top performance.
ConVEx uses a novel unsupervised pre-training objective to train an entire value extraction model on billions of sentences. Slot-specific models can then be learned on small amounts of labeled data by simply fine-tuning a few parameters, outperforming more complex specialized few-shot learning algorithms, and fine-tuning approaches that require training new layers from scratch.
The ConVEx framework achieves state-of-the-art performance across a range of diverse domains and data sets for dialog slot-labeling, with the largest gains reported in the most challenging, few-shot setups. ConVEx’s reduced pretraining times (i.e., only 18 hours on 12 GPUs) and cost, along with its efficient fine-tuning and strong performance, enable wider portability and scalability for data-efficient sequence-labeling tasks in general.
Pairwise Cloze Pre-training
Top performing natural language understanding models – such as BERT or PolyAI’s ConveRT – typically make use of neural networks pre-trained on large scale datasets with unsupervised objectives. For sequential tasks, such as slot-labeling, this involves adding new layers and training them from scratch, as the pre-training does not involve sequential decoding. This is suboptimal, and with ConVEx, we introduce a new type of pre-training that:
- is more closely related to the ultimate slot-labeling task
- includes all the necessary layers for slot-labeling, so these can be fine-tuned rather than learned from scratch
We introduce the pairwise cloze for training ConVEx. Given a pair of sentences that have a key phrase in common, the key phrase is masked in one sentence (the Template sentence), and the model must predict it in the other sentence (the Input sentence):

Training on this task, the model learns an implicit universal space of slots and values, where slots are represented as the contexts in which a value might occur. Using a simple keyphrase identification process, we obtain 1.2 billion examples from the Reddit corpus of conversational English.
ConVEx
We built the ConVEx neural network structure on top ConveRT, a highly optimized transformer network. The below figure gives an overview of the structure, and full details are given in our paper. After encoding through ConveRT, sequence decoding layers use self-attention, attention and CRF layers to decode the target sequence labels.
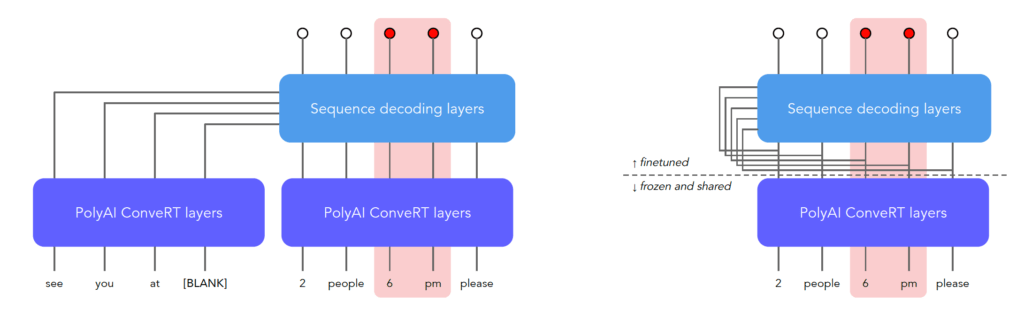
Right: ConVEx fine-tuning on slot-labeling data
After pre-training on billions of pairwise cloze examples extracted from Reddit, ConVEx is fine-tuned on domain-specific slot-labeling data. The majority of the model is frozen, and only the decoding layers are fine-tuned, allowing for efficient inference and sharing of computations across domains and slots. For slot-labeling, there is no concept of a template sentence, so the user utterance is fed in as both the template and input sentence.
Evaluation
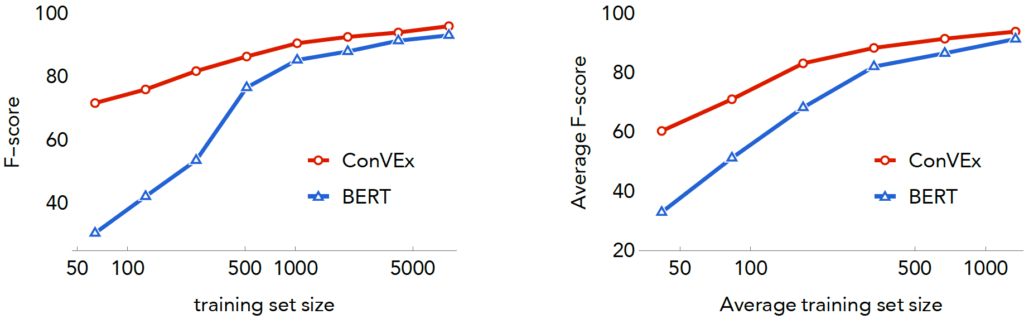
Right: DSTC8 SGDD Data (4 domains)
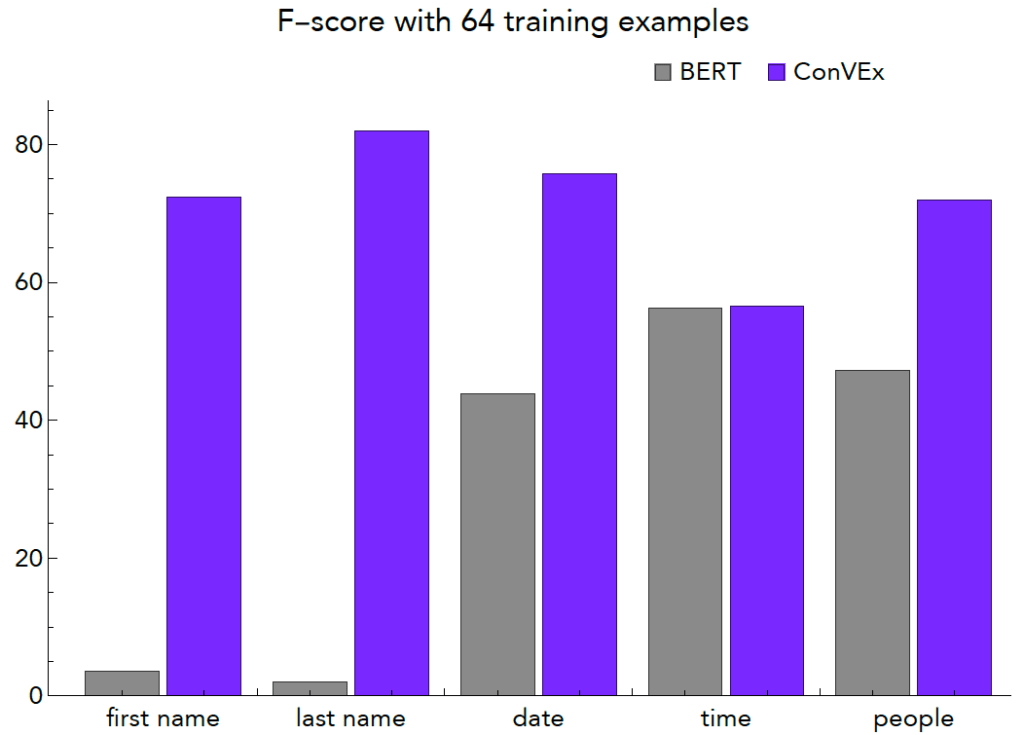
We evaluate the ConVEx framework across a wide variety of dialogue domains and training conditions in our paper. The graphs above summarize the performance of ConVEx relative to a competitive BERT model, with a varying amount of training data. ConVEx requires far less data for a given level of performance, and is of course far smaller, efficient, and cheaper to train than a model like BERT. For example, with only 64 training examples of the last name slot, BERT achieves an f-score of 2%, while ConVEx achieves 82%:
Our paper also presents a few-shot evaluation over 7 dialogue domains with as few as 5 examples available for fine-tuning, where ConVEx consistently outperforms specialized computationally expensive few-shot algorithms based on BERT.
Conclusion
The ConVEx framework achieves a new leap in performance, by aligning the pre-training phase with the downstream fine-tuning phase for sequence labeling tasks. In particular, the inclusion of all the required layers for the downstream task in the pre-training process enables the use of a simple fine-tuning procedure. The resulting model is efficient, fast and cheap to train, and shares computation across slots and even deployments.
The advantages of ConVEx are particularly apparent in the challenging few-shot and low-data conditions. ConVEx allows us to train highly accurate models with far less data than our competitors, allowing us to build new systems and features quickly and inexpensively.


