

This is a deep-dive into one of the problems we face when we model dialogue: understanding mentions of people’s names in a restaurant booking system. This article presents how we approached the problem and solved it using some creative neural network structures.
At PolyAI, we use datasets of billions of conversations and unstructured natural language texts to learn powerful deep neural models of conversational response. These models allow us to embed any conversational context or response into a shared high-dimensional vector space, so we can retrieve relevant responses, answers, entities and even photos from large databases comprising in-domain knowledge. Comparison of embedding vectors can also facilitate intent detection, i.e. classification of spoken language into specific categories such as ‘make a booking’ or ‘confirm booking’.
In this way, we can exploit a large ranker model and its internal implicit semantic vector space to solve many of the problems in dialogue, without hand-designing any explicit semantic structures like dialogue acts.
But some tasks in dialogue require explicit tracking, such as obtaining the details of a restaurant reservation. We must obtain the user’s name and phone number, as well as the time, date, and number of people for the reservation, so the details can be used in an API call.
Dates, times, and phone numbers can be matched with high recall using grammars and regular expressions. Such pattern matching modules can be effectively combined with neural classification models and relevant dialogue data to track these slots with high accuracy. This provides a robust method of explicitly tracking slots in many dialogue domains, though we focus on restaurant reservation here.
Established methods for named entity recognition cannot be directly applied to tracking people’s names in a restaurant reservation system. It is a tricky problem for several reasons:
- It’s for June. Depending on the context, this might be a mention of the first name June, or the month. There are other names that are also common English words, such as Brown or even The.
- Tyler, party of three. Some names like Tyler can be either a first or a second name.
- A table at Matt H’s Café. While this is a mention of a name, it is not the user saying their own name.
- It should be under Pei-Hao Su. It is hard to construct a conclusive list of names. A system that is limited to matching against a list is likely to not recognise rare names.
While capitalisation is a strong feature for indicating names in written text, this information is not available in a speech signal without applying further statistical models.
Other conversational AI applications that ask for people’s names can employ tricks, such as using the names in your contact list to bias results (“Hey Siri, call Gillian”), or avoiding the problem by already knowing your name. However for our use case of restaurant reservation, we must be able to accept any name, without knowing in advance who they might be.
At PolyAI, we started with a system that relied on a list of possible people’s names, and then developed an end-to-end neural approach that does not rely on a list, and achieves higher accuracy.
Data
To train and evaluate methods for tracking people’s names, we collected data in the restaurant reservation domain with first and last names labelled. We used a mixture of user logs and crowd-sourced sentences. The labelling task was simplified using an initial high-recall system.
This gave us 10,000 examples for training and 4,000 examples for evaluation.

We also stored one bit of context, whether the system just asked for the user’s name, to allow disambiguation in cases like “It’s for June” and to help bias name recognition.
People’s names list and classification
Our first approach employs a large list of first and second names, and looks for occurrences of these names in the user’s input. This is done efficiently with the Aho-Corasick algorithm. This provides very high recall, i.e. it identifies most names, but very low precision, i.e. most of the names it returns are not real occurrences.
We train a classifier to take the high-recall output from the names list, filtering out bad suggestions, and resulting in high-precision output.
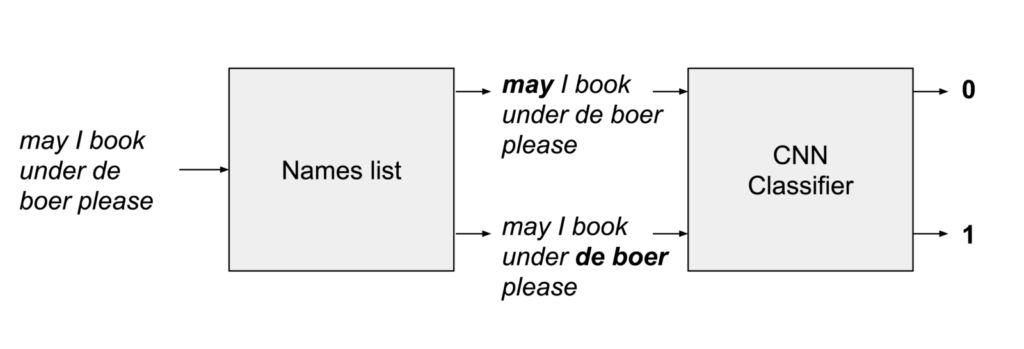
This type of approach also works well for times, dates, phone numbers, and other things that can be identified with high recall, though possibly low precision.
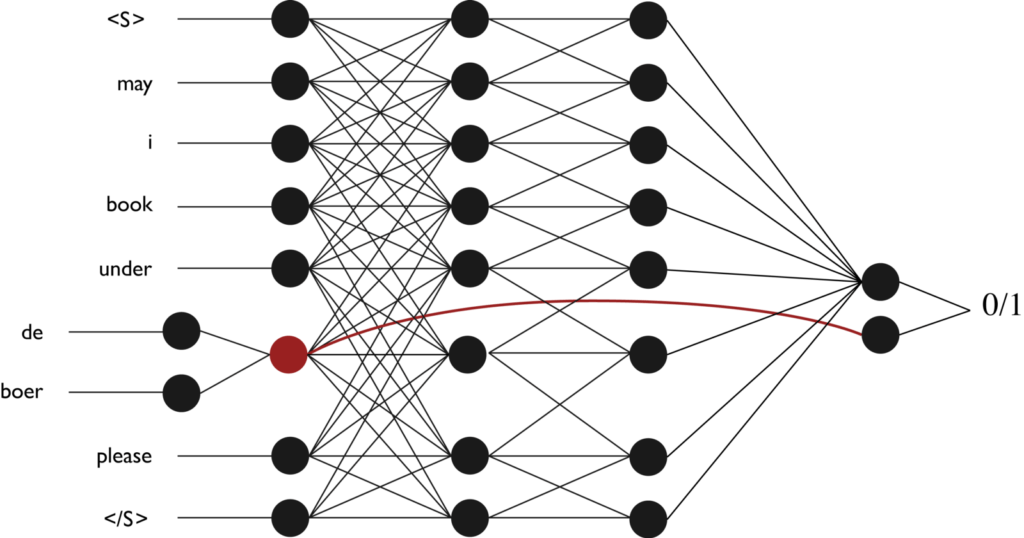
The classifier itself is a convolutional neural network (CNN), that encodes the proposed sub-span in the context of the user’s input, and is trained to detect whether or not this is a true occurrence of the user specifying their name.
End-to-end neural approach
We seek to design a single neural network that can do the combined job of the name list and classifier, that takes text as input and directly predicts which sub-span of the text corresponds to a name, if any. Such a model would not require or be limited to a list of names.
Standard approaches for feeding text as input to a neural network use a vocabulary of known words or tokens, and have a limited ability to interpret words outside the vocabulary. When dealing with names, it is important for the model to be able to interpret rare words, as many names are rarely or never seen in training.
To address the issue of out-of-vocabulary words, we first split sentences into subword tokens, where each token is known, and in the worst case is a single character (Shuster and Nakajima, Sennrich et al). Such a tokenisation is also reversible, which makes it easier to find the correspondence of the label to tokens, and to convert predicted token spans into strings.
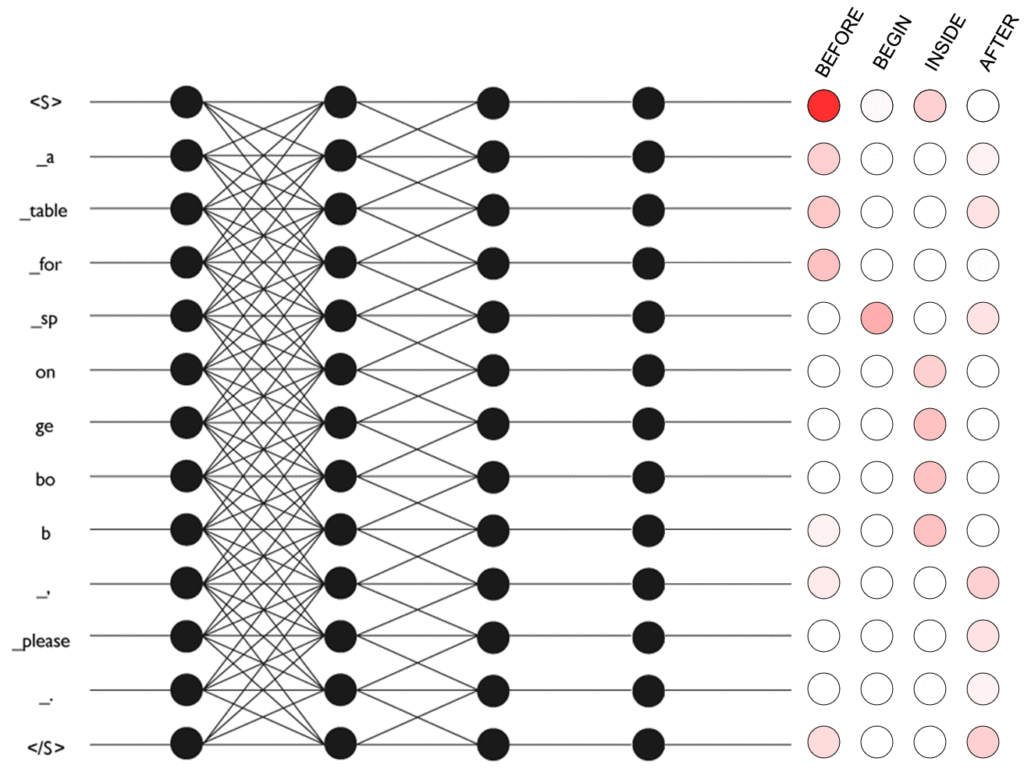
Subword tokens are embedded, and then passed through several convolutional layers. The final layer predicts the parameters of a linear-chain conditional random field (CRF). The CRF identifies the correct sub-span using BEFORE, BEGIN, INSIDE and AFTER tags as shown in the diagram.
This is similar to the paper by Ma and Hovy, but they use a mixture of character-level and word-level networks to deal with out-of-vocabulary tokens. We believe the subword token approach is a natural middle-ground between words and characters, which can simultaneously memorise meaningful embeddings for frequent words while constructing meaningful representations of rare words.
Evaluation
We evaluated the precision and recall of each approach, as well as the f-score. The precision measures how often a name suggested by the system is correct, while recall measures how often the system includes the correct name in its suggestions.
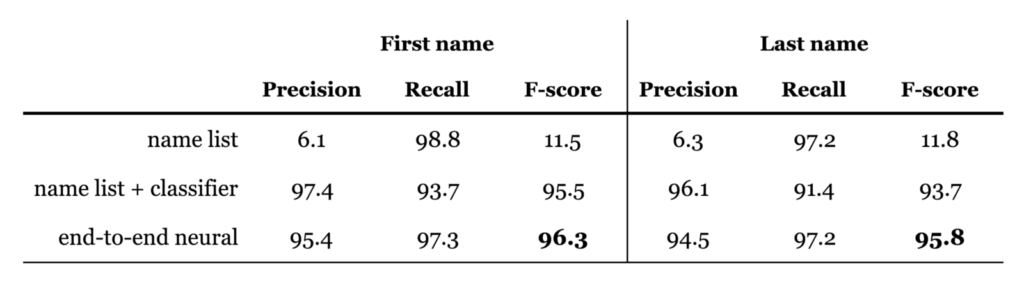
Using a name list alone gets high recall, but of course it gets very bad precision as it suggests every single match of something on its list. Combining the names list with a binary classifier vastly improves the precision, at the cost of some recall. Overall the end-to-end neural approach works best in terms of f-score, gaining high recall and precision.
The end-to-end neural network learns from data how names look on the lexical level. It can easily adapt to new names, such as those containing unicode characters, spaces, hyphens etc.

Conclusion
Large neural network models, trained on billions of examples, with rich embedding spaces allow us to model many aspects of dialogue. But each individual domain, such as restaurant reservation, always requires us to solve new specific challenges with high recall and precision. The task of identifying and tracking people’s names at first sounded simple but turned out to be a rich problem.
It would be practically impossible to enumerate every single possible name. We avoided this by using a data-driven neural approach, capable of reading any string of text with subword tokens. This approach does not require, nor is it limited to, a list of possible names, and it makes higher quality predictions. Hand-written grammars and matching rules (such as triggering on “My name is X”) could also have been considered, however learning these patterns from data is more scalable in terms of adapting to new domains and languages, and likely more robust.
When faced with problems like this at PolyAI, we first make them measurable with a meaningful evaluation, and make progress towards more and more accurate systems using our experience in dialogue and creativity in machine learning.
Thanks to my colleagues at PolyAI, in particular to Sam Coope who worked on this project with me.
Thanks to Ivan Vulić.


