
Progress in Machine Learning is often driven by large datasets and consistent evaluation metrics. To this end, PolyAI is releasing a collection of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation framework for models of conversational response selection.
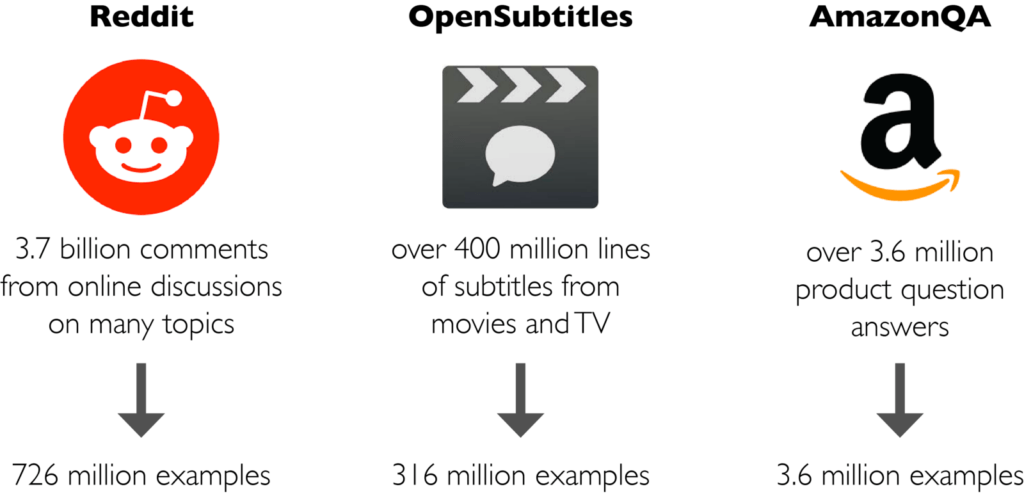
Conversational response selection, the task of identifying a correct response to a given conversational context, provides a powerful signal for learning implicit semantic representations useful for many downstream tasks in natural language understanding. Models of conversational response selection can also be directly used to power dialogue systems, question answer features, and response suggestion systems.
We hope that these datasets can provide a common testbed for work on conversational response selection. The 1-of-100 accuracy metric, which measures how often the correct response is selected over 99 random responses, allows for direct comparison of models.
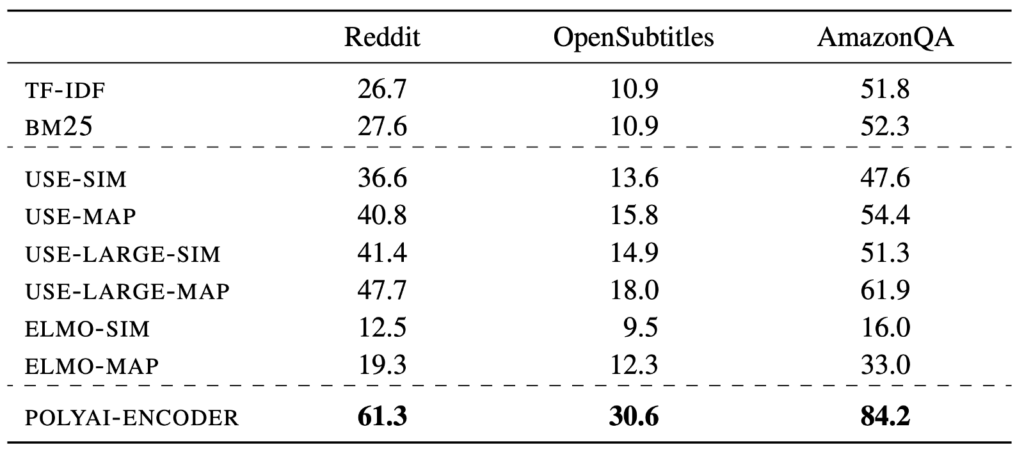
For full details, see the Conversational Datasets GitHub repository, and our paper on arXiv. The GitHub repository contains scripts to generate these datasets, implementations of various conversational response selection baselines, and tables of benchmark evaluation results.
We welcome contributions to the GitHub repository, for new datasets, new evaluation results, new baselines etc.
Thanks to my colleagues at PolyAI.


