
Speaking more languages simply means reaching more people. This statement is equally true when it relates to humans or to conversational AI systems. The transformative nature of polyglot AI technology opens up new opportunities by catering to wider audiences and offering multilingual solutions. At PolyAI, our mission is to overcome the language barriers through our data-driven and language-invariant philosophy of composing or orchestrating conversations.

Imagine being able to call your favourite Peruvian or Korean restaurant in Lima or Seoul to book a table using your native language, be it Basque, Slovak, Mandarin, any language out of 19 languages spoken at PolyAI, or virtually any other language. In another scenario, imagine being able to book your flight simply by having a short conversation without wasting your time searching online, again in your native language. Climbing to the top of this tower of words and meanings, that is, completely bridging the gaps and barriers between the languages of the world still sounds utopian although we have witnessed some substantial progress recently.
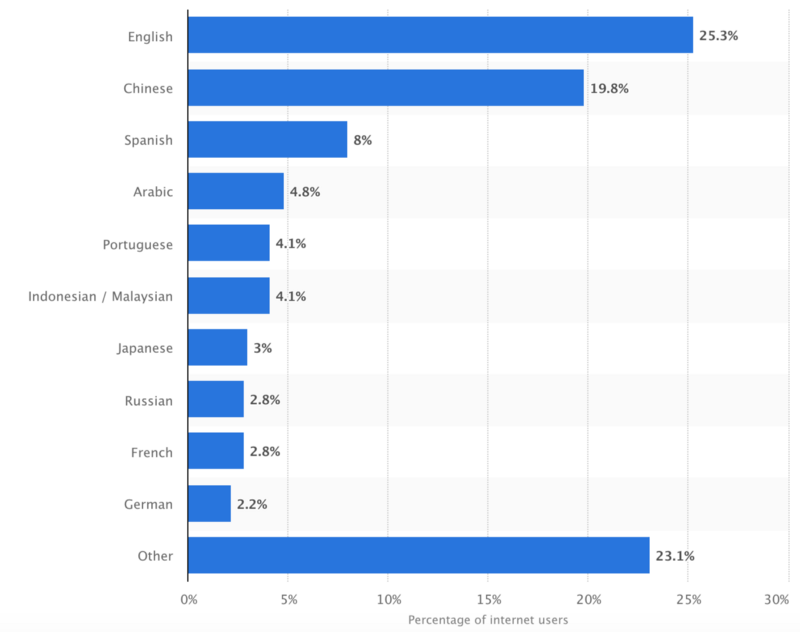
The positive momentum is tightly related to the rise of data-driven deep learning models which power our statistical machine translation, multilingual speech processing, and natural language understanding systems. However, despite steady improvements in this landscape, we are still living in the age of the digital language divide. For instance, while all the 24 official languages of the European Union enjoy equal status de iure, there is still tremendous disparity in language technology available between major languages with larger markets such as English or Spanish and languages with less native speakers such as Maltese or Latvian. A similar situation is observed at the global scale, where the top 10 languages cover more than 77% of the entire Internet population. Even if we put the storyline of the digital language divide aside, the same stats provide another invaluable lesson: while still dominant as the lingua franca of information technology, if we focus solely on the English language when building our conversational AI technology, we immediately cut out a large pool of potential users and customers who prefer their native language to English.
In other words, whether the goal be reaching to new large audiences and expanding the market, or mitigating the global digital divide in language technology by offering products in minor languages and dialects, multilingual or “polyglot” dialogue systems are the natural (and even mandatory) next step in the continuous evolution of conversational AI technology. Economic and societal benefits of such multilingual tools are massive. They span the long-term vision of the complete digital transformation through seamless access to all multilingual information available online and the creation of digital single market, as well as the more feasible and more immediate applications covering the localisation of our intelligent virtual assistants and smart appliances, or more efficient multilingual contact centres and customer services.
Are We There Yet?
Despite the obvious advantages of multilinguality, development of conversational AI in many languages still lags way behind solutions for major languages such as English, Spanish, or Mandarin. The reasons are quite prosaic. First, as discussed in one of our previous blog posts, current popular approaches to dialogue data collection are time-consuming, expensive, and rely on very complex annotations. Because of this, building multilingual task-oriented dialogue systems has been simply infeasible if one wants to work with a large number of languages. Second, many cutting-edge solutions to conversational AI such as the ones found in popular chatbots and intelligent virtual assistants still largely depend on rule-based decision-tree style design of conversational flows. In other words, if the system designers expand the system to a new language, the integration is far from being quick and seamless. The designers are forced to adapt conversational flows to the target language, and this script-writing approach to dialogue just does not scale well. Third, the costs of these complex language-specific procedures to procuring annotated dialogue data or writing dialogue scripts are the main reason why the focus of multilingual conversational AI is still confined only to major languages with large markets. However, in our age of information with increasing investments into alleviating digitally created biases such as the access to language technology (or the lack of it), shouldn’t we also move beyond the sheer language market size and enable the same technology on a wider scale?
PolyAI’s Approach: Composing Multilingual Conversations
At PolyAI, we believe in the process of democratising conversational AI and aim to develop highly scalable tools that can be ported to a multitude of languages. The solution which supports the PolyAI platform is to sidestep both the complexity of collecting annotated dialogue data and the need to over-engineer the system. The two-step procedure of conversational searching and content programming used at PolyAI lends itself naturally to multilingual settings. The first phase relies on a conversational search engine trained on a large corpus comprising billions of past conversations available in a resource-rich language (e.g., English) augmented by the data from multiple other languages. The developers then curate the content using content programming in any of their preferred languages. Given the user’s input utterance in any supported language, the system then performs on-the-fly automatic translation from the input language to the language of the search engine. The most appropriate system responses are then translated back to the input language and made more fluent using a pre-trained language model. This procedure leverages a large conversational search engine by using machine translation tools without actually suffering from MT-introduced errors.
Note that the translations in the first phase need not be perfect: this crude polyglot search engine can be further honed in the second phase of content programming. The elegance of this approach which focuses on composing multilingual conversations is that we put our trust in large and readily available datasets which power the training of our conversational search engines, our machine translation systems, and our language models. These data are much cheaper to obtain than dedicated and sufficiently large annotated datasets for each task or domain and each language. In fact, they are not only cheaper: unlike the latter they actually do exist. What is more, by composing multilingual dialogues, we effectively bypass the problems of natural language understanding, generation, and decision making, which often result in cascading errors in standard modular conversational systems.
What Can We Still Improve?
While I have outlined the main framework which enables conversations in multiple languages, the playground of multilingual natural language processing is so huge that I have only scratched the surface in this text snippet. Although our conversational solution is conceptually simpler than the alternatives, it is still a multi-component system where improvements of constituent components will undoubtedly result in improvements of our “conversational compositions”. Being fully aware of these dependencies, we are actively working in all these exciting research areas. For instance, one essential component that enables conversational search in the first place concerns learning semantically meaningful representations (i.e., encodings) of system responses and user utterances. This research field has seen a lot of movement recently within NLP and Machine Learning communities with the introduction of contextualised representations and sentence encoders such as Universal Sentence Encoder, ELMo, GPT, and most recently BERT and our own PolyAI encoder. To fully unravel the potential of multilingual data, the next steps involve further refinement of these encoders and their extensions to multilingual settings, as already started with, e.g., multilingual BERT, cross-lingual ELMo, or LASER (Language-Agnostic SEntence Representations). Remarkably, these developments in text representation that effectively transformed the world of NLP are still very fresh: they all happened in 2018 and 2019, and are happening now as you read this text. This means that we still do not completely understand their full potential, and how to exploit that potential in multilingual text representation learning.
Speaking of speech recognition and speech synthesis modules, they are still not fully developed for a large number of languages, and many times the only feasible solution is to fine-tune these modules through language transfer from a similar language (or a set of languages) that already has these modules sufficiently developed (e.g., we can rely on speech recognition in Croatian, Serbian, or Bulgarian to improve speech recognition for Macedonian). Furthermore, our conversational system relies on automatic machine translation systems which may not be available for all target language pairs, but very recent research has invested much effort into creating increasingly powerful multilingual MT systems that can even learn with very limited multilingual supervision. Future developments in our translation systems will of course be consequently reflected in our improved ability to handle multilingual conversations. Since our framework is data-driven, collecting more data for training and fine-tuning our polyglot conversational engine and multilingual language models should also be quite helpful, right?
Finally, besides these fundamental research areas for multilingual conversational AI modelling, it also remains to be seen how to deal with other related phenomena such as code switching, or how to model dialects and non-standard language varieties, or how to provide support even to languages with limited digital footprint.
Conclusion
From weather forecasts over tourist information to specialised contact centres, enabling multilingual communication is one of the crucial long-term goals of conversational AI. Besides bridging the digital divide and offering solutions to a larger number of users, multilingual conversational AI can also serve as a valuable support for the increasing number of multilingual households that according to some statistics even outnumber monolingual households these days. In this blog post I have provided a very brief overview of some of the current challenges in multilingual conversational AI modelling, and PolyAI’s current perspective on this subject. Having a highly diverse and international team of researchers and engineers, PolyAI’s abiding mission and responsibility is to extend our data-driven conversational AI philosophy to a wide variety of languages, and to build highly scalable solutions that go hand in hand with the needs of the increasingly diverse polyglot society.
Thanks to my colleagues at PolyAI, in particular to Tsung-Hsien Wen for reading previous drafts of this text.


