
Unlike open-domain dialogue systems which focus on free-flowing conversations with no particular objective, Task-Oriented Dialogue (TOD) systems are designed with a goal in mind. They allow users to solve problems through the medium of natural language, making them perfect for automating customer service queries and transactions.
TOD systems require a huge amount of data in order to accurately classify intents. But data is costly and time consuming to obtain and annotate. In this blog post, we propose a new, more efficient and more precise system for NLU design that:
- Allows for more accurate intent classification with less data
- Allows more data to be reusable across different domains and applications
NLU for dialogue is a unique machine learning problem
Consider speech recognition. This is a machine learning problem that also requires a lot of data. This data can be annotated relatively simply by a person listening to a recording and transcribing what is said.
With machine translation, there are many different ways to annotate data depending on the languages being translated from and to. But once the annotation has been done, the data is reusable across almost any application or domain.
NLU for dialogue is a more complex problem in that there is no standardised way of annotating data that will apply across different domains.
Take a look at the following example.
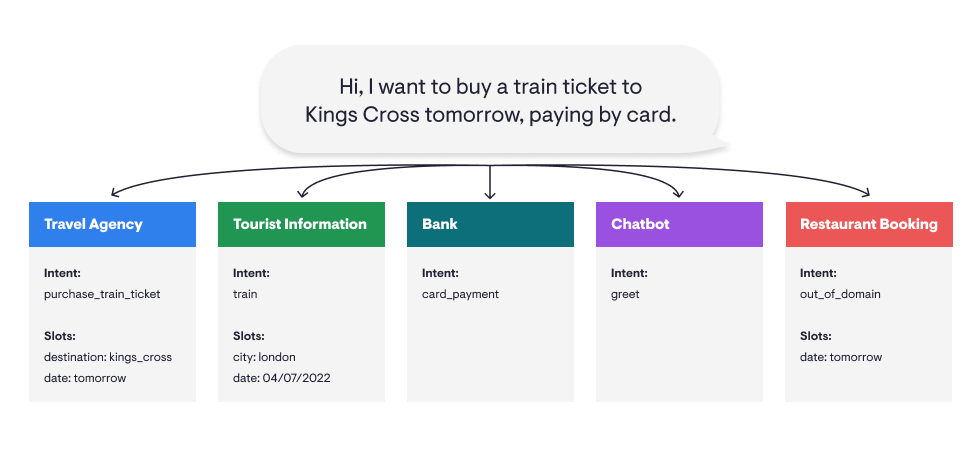
The caller says “I want to buy a train ticket to Kings Cross tomorrow, paying by card.”
In a travel booking application, the NLU will be designed to understand that the user is trying to book a train ticket.
However, in a banking application, the NLU will be designed to understand the utterance as a query about card payments. In a restaurant application, the NLU won’t extract any useful information..
In other words, the way information is classified depends on the domain.
Why does this happen? Think about the meaning of slots, values, intents… These are arbitrary symbols that only make sense in the context of the domain. In other words, the symbols have been designed for a specific application.
To create a dataset that can be reused between applications and domains requires a new approach to annotation.
The problem with domain-specific information classification
Classifying intents based on the context of the domain creates several issues:
- Domain expertise is necessary to annotate the data. The annotators need to know what each intent or slot means or represents in the context of the domain. Sometimes, boundaries between intents are not clear, even for expert annotators.
- Annotations are not reusable from domain to domain. What could be annotated as BANK_TRANSFER in one domain could mean TRANSFER_TO_OPERATOR in another
- The annotations are extremely tied to the ontology. Therefore, changes in the ontology (e.g. due to the client changing the specs) require a lot of reannotation work.
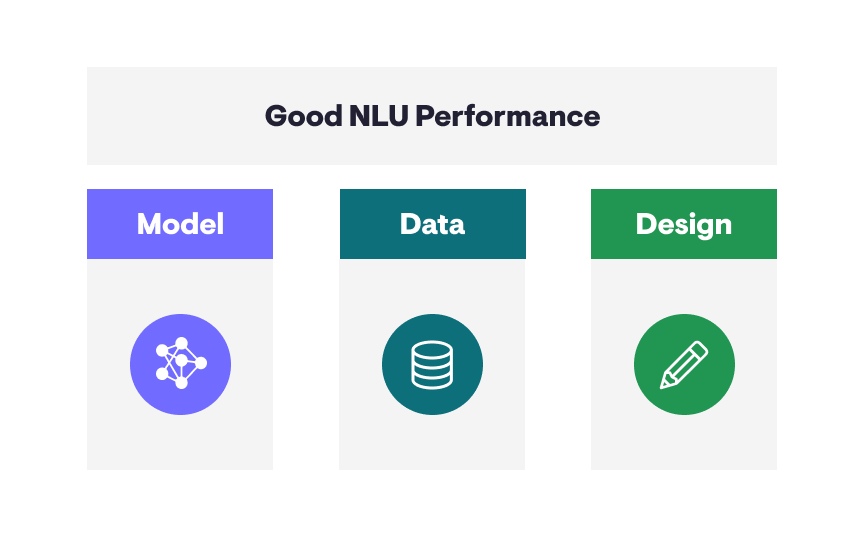
The three pillars of good NLU performance
This raises one of the biggest problems in TOD systems: Data is extremely expensive. Data is one of the pillars of good NLU performance, but is it feasible to collect thousands of in-domain annotated sentences every time we deploy a new system?
The main way to tackle this problem has been through another of the pillars of NLU: the model. At PolyAI, we have been leading research on data efficient models, allowing us to reduce the amount of data needed to deploy our systems.
However, there is a third pillar that is often overlooked and neglected: design.
The first step in setting up any dialogue system should be understanding the domain and designing an ontology adapted to the clients specs. This will require less data, have a better NLU performance and make our system easier to maintain and scale.
Traditional single intent design
The complexity of the NLU depends on the task we are trying to solve.
An intent detection model will easily differentiate between “set up an alarm” and “tell me the weather”. However, in real systems, the boundaries between intents are less clear.
In a banking application, we might need to differentiate between “my transaction was rejected” and “my transaction is on hold”. As these sentences are semantically and lexically very similar, the model will have a very hard time differentiating them.
These are conflicting intents. They are essentially “fighting” for the same semantic space, because the semantics of these intents partly overlap.
Let’s think about a larger set of sentences, and how a traditional single-intent style design would annotate them:
Sentence | Single Intent Annotation | |
1 | “I want to send some money” | MAKE_TRANSFER |
2 | “I need to cancel a transfer” | CANCEL_TRANSFER |
3 | “I need to remove a direct debit” | CANCEL_DIRECT_DEBIT |
4 | “Can I modify a direct debit?” | CHANGE_DIRECT_DEBIT |
5 | “I was trying to make a transfer but it doesn’t let me” | MAKE_TRANSFER_NOT_WORKING |
6 | “I am unable to remove a direct debit” | CANCEL_DIRECT_DEBIT_NOT_WORKING |
However, some of these sentences have semantic overlap. Sentences 1 and 2 both contain the overlapping concept “transfer”, while sentences 2 and 3 both contain the concept “cancel”. This can create conflicts.
We therefore propose a method that will enable the model to learn these concepts independently by modularising the intent space.
Modular intent design
To do this, we will design the intent space so that the semantic overlap between intents is minimized: i.e. define the set of intents as MAKE, CANCEL, CHANGE, NOT_WORKING, TRANSFER and DIRECT_DEBIT.
With this design, the annotations will look like:
Sentence | Modular Intent Annotation | |
1 | “I want to send some money” | MAKE, TRANSFER |
2 | “I need to cancel a transfer” | CANCEL, TRANSFER |
3 | “I need to remove a direct debit” | CANCEL, DIRECT_DEBIT |
4 | “Can I modify a direct debit?” | CHANGE, DIRECT_DEBIT |
5 | “I was trying to make a transfer but it doesn’t let me” | MAKE, TRANSFER, NOT_WORKING |
6 | “I am unable to remove a direct debit” | CANCEL, DIRECT_DEBIT, NOT_WORKING |
The benefits of modular intent design
Putting a small extra effort on the design of the intent space results in a number of benefits:
- Less data required: Lower intent overlap means better model performance, therefore less data is required (effectively reducing the data collection and annotation effort).
- Reduced intent set: Breaking down intents into intent modules effectively reduces the size of the intent set, even though we can express many more ideas by combining the intent modules.
- Handling disambiguation: Multi-turn conversations often have disambiguation turns. E.g. the user might have said something about a booking, but hasn’t specified what. Then the system could ask “do you want to make, amend or cancel a booking?”, to which the user will probably answer something like “make one” or “cancel it”. Breaking down intents in modules lets the policy act more intelligently in these situations.
- Better generalization capabilities: Modular intents increase the generalization capabilities of the model. E.g. If the user says “I want to make a direct debit”, the model can correctly predict the MAKE and DIRECT_DEBIT intents even if we don’t have any sentence that combines them in the training data, as long as we have sentences that have the intents separately. In a single intent approach, the MAKE_DIRECT_DEBIT intent could never be predicted if we don’t have any examples of it.
- Easier scalability of the model: A modular design eases the expansion of the system specs. For example, if the client asks to expand the system to be able to MAKE, CHANGE, and CANCEL appointments, we will only need to add the APPOINTMENT intent.
Finally, when dividing the intent in modules, generic-and domain-specific intents naturally arise. We will talk about this in the next section.
Generic- vs domain-specific intents
Think about the problem mentioned in the introduction: TOD datasets are not reusable across domains because of the lack of output space standardization.
However, once we do a modular division of intents, we observe how some of these intents recurrently appear across domains. E.g. while TRANSFER and DIRECT_DEBIT are clearly related to a banking domain, MAKE and CHANGE could appear in other domains, such as restaurant booking (“I want to make a booking”, “can I change my reservation?”) or a public service application (“How do I submit a birth certificate?”, “I just got married, I need to change my last name”).
Examples annotated with generic intents can be reused in other domains, allowing us to set up new systems more quickly, increasing consistency between ontologies, and eventually being able to create universal generic intent detectors, avoiding the need to annotate generic intents at all!
Keyword intents
When we modularise the intent space, we observe another pattern. Some intents such as NOT_WORKING or CHANGE can be expressed in many different ways, thus the need for a statistical intent classifier. However, when we modularise the intents, we observe that some intents can only be expressed in one or a few ways. For example, whenever we see the words “direct debit” we know that it can only mean DIRECT_DEBIT. Therefore, we can just define a keyword or a string of keywords in order to detect it instead of collecting and annotating costly examples.
When is an intent a keyword intent?
However, it’s very important to identify when we can define an intent as a keyword intent:
- The intent has very low lexical variability (can only be expressed in a handful of ways)
- The keywords used are rare words or rare combinations of words (e.g. restaurant names, product names, etc.)
- We are 100% certain that the keywords cannot have any other meaning if we change the context.
Henceforth, it’s very important once again to understand the domain to design the ontology accordingly, identifying which intents could be defined as keywords.
Conclusion
At PolyAI, we’re not only data-centric or model-centric, we’re also design-centric and aware that these three pillars have to work in synergy.
In this blogpost, we have discussed how PolyAI’s investment into one aspect of the NLU design process – intent modularisation – already pays off in higher-quality systems and quicker turnaround and development times. In addition, we have released a public dataset in order to ease research on modular intent detection. Being ‘design-centric’ is the first step towards easier data creation and collection, better-performing and more sample-efficient models, and preventing issues that arise because proper consideration has not been given to design.
Read the full paper at Arxiv.


